RAG系统数据安全架构研究报告
核心问题解答
热门问题:RAG在调用公网的SaaS LLM API时,如何保证数据安全不被泄露?
简要答案: RAG系统通过多层安全架构在数据发送到外部API之前进行保护,包括PII脱敏、权限检查、上下文压缩、输入输出护栏等机制。企业级RAG将敏感数据保留在本地,仅将经过清洗和最小化的上下文片段发送给外部LLM,从而在利用强大AI能力的同时保护数据主权。
一、RAG架构基础
1.1 RAG工作原理
RAG(Retrieval-Augmented Generation,检索增强生成)系统由两个核心管道组成:
graph LR
subgraph "索引管道(离线/异步)"
A[数据源] --> B[文档解析]
B --> C[文本分块]
C --> D[向量化编码]
D --> E[向量数据库]
end
subgraph "生成管道(在线/实时)"
F[用户查询] --> G[查询向量化]
G --> H[向量检索]
E --> H
H --> I[上下文增强]
I --> J[发送到LLM API]
J --> K[生成响应]
end
关键数据流:
- 索引阶段(离线):企业文档 → 清洗 → 分块 → 向量化 → 存储在本地向量数据库
- 查询阶段(在线):用户问题 → 检索相关文档片段 → 安全过滤 → 构建提示词 → 调用外部API → 返回结果
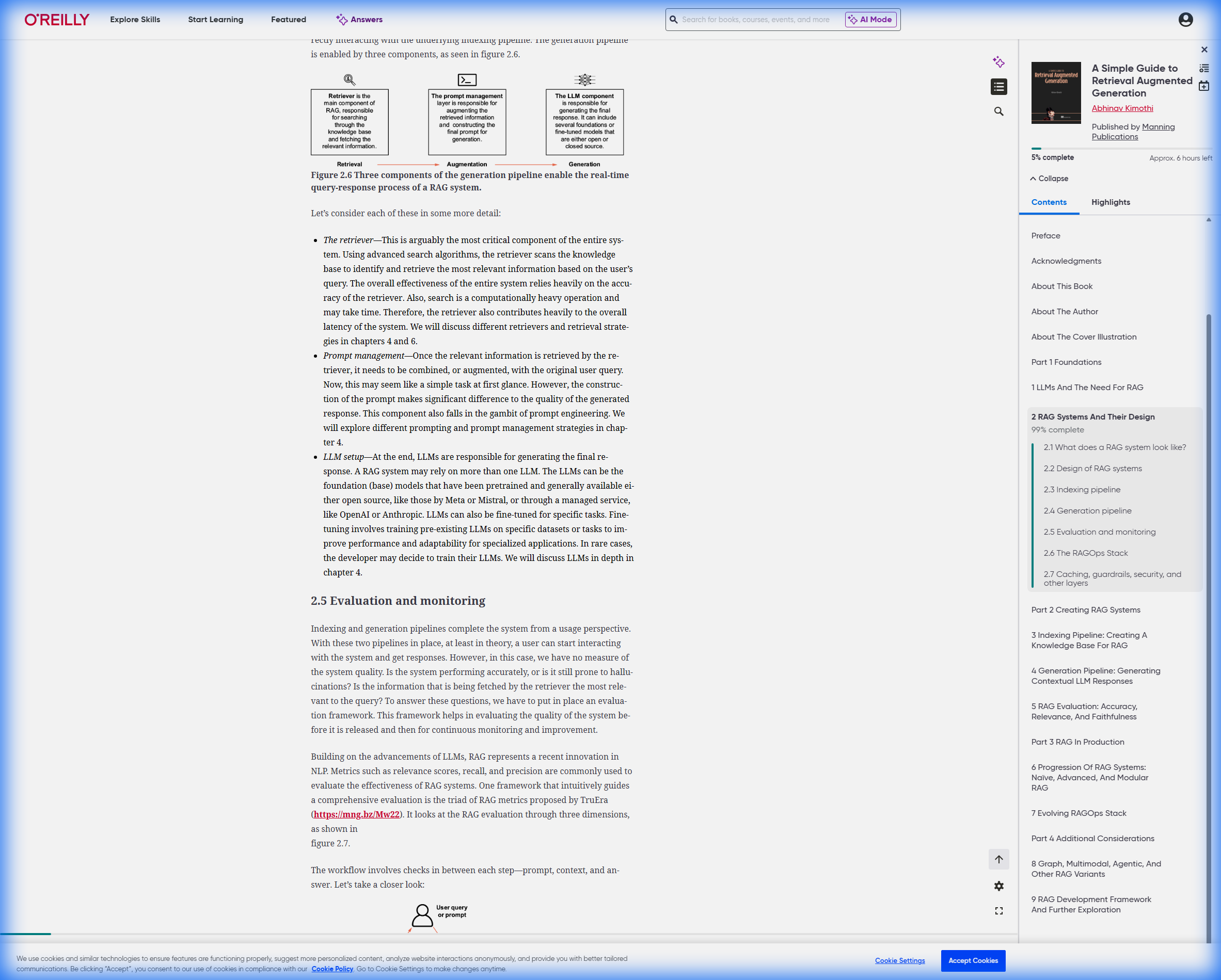
1.2 核心架构模式(微服务分解)
根据《Mastering Retrieval-Augmented Generation》,企业级RAG采用微服务分解模式:
- 查询服务(Query Service):请求验证、用户权限检查
- 检索服务(Retrieval Service):向量搜索、文档级访问控制
- 生成服务(Generation Service):作为安全代理调用外部LLM API
- 嵌入服务(Embedding Service):独立处理向量转换
- 多层缓存(Caching):减少API调用次数,降低数据暴露
二、数据安全保护机制
2.1 五层防护体系
第1层:输入端安全(查询验证)
| 机制 | 说明 | 来源 |
|---|---|---|
| 查询清洗 | 规范化用户输入,移除特殊字符 | Haystack Book |
| 提示词注入防护 | 检测并阻止恶意提示词(如”忽略之前的指令”) | AI-Native LLM Security |
| 速率限制 | 通过API网关限制单用户请求频率 | Haystack Book |
第2层:检索端安全(权限过滤)
| 机制 | 说明 | 来源 |
|---|---|---|
| 基于角色的访问控制(RBAC) | 根据用户身份过滤可检索文档 | Mastering RAG |
| 文档级分类标签 | 标记文档为Public/Internal/Confidential | AI-Native LLM Security |
| 租户隔离 | 多租户环境下使用WHERE tenant_id = current_user()防止跨租户泄露 |
AI-Native LLM Security |
| 权限感知检索 | ANN搜索结果与用户allowed-doc-id列表求交集 |
AI-Native LLM Security |
第3层:数据脱敏(发送前处理)
[!IMPORTANT] 这是防止数据泄露到外部API的核心防线
| 机制 | 说明 | 实现方式 |
|---|---|---|
| PII自动检测与脱敏 | 识别并屏蔽个人身份信息(SSN、邮箱、电话等) | 正则表达式 + 专用NER模型 |
| 上下文压缩 | 只发送最相关的文本片段,而非完整文档 | LLMLingua / Contextual Compression |
| 数据最小化原则 | 仅传输回答问题所需的最小信息集 | 设计原则 |
| 差分隐私 | 在输出中添加噪声,防止成员推断攻击 | AI-Native LLM Security |
| K-匿名化 | 确保任何记录至少与k-1条其他记录无法区分 | AI-Native LLM Security |
示例:
1
2
3
4
5
6
7
# 发送前
- "客户张三的身份证号为110101199001011234,手机号13800138000"
+ "客户[姓名]的身份证号为[已脱敏],手机号[已脱敏]"
# 上下文压缩
- 发送完整10页合同文档
+ 仅发送包含答案的3个关键段落(约500 tokens)
第4层:传输与API安全
| 机制 | 说明 | 来源 |
|---|---|---|
| TLS 1.3加密 | 所有与外部API通信强制使用最新加密协议 | Mastering RAG |
| 短期令牌 | 使用有效期≤1小时的JWT,降低凭证泄露风险 | Mastering RAG |
| 零信任架构 | 外部化密钥到HashiCorp Vault/AWS KMS | AI-Native LLM Security |
| 行为指令替代硬编码密钥 | 提示词中使用”调用payment_charge”而非直接嵌入API密钥 | AI-Native LLM Security |
第5层:输出端安全(响应后处理)
| 机制 | 说明 | 来源 |
|---|---|---|
| 输出过滤 | 检查LLM响应是否泄露系统提示词或未授权信息 | Simple Guide to RAG |
| 内容合规检查 | 确保输出符合道德和法律要求 | Haystack Book |
| 审计日志 | 记录哪些文档被用于生成哪个回答(GDPR/HIPAA要求) | Mastering RAG |
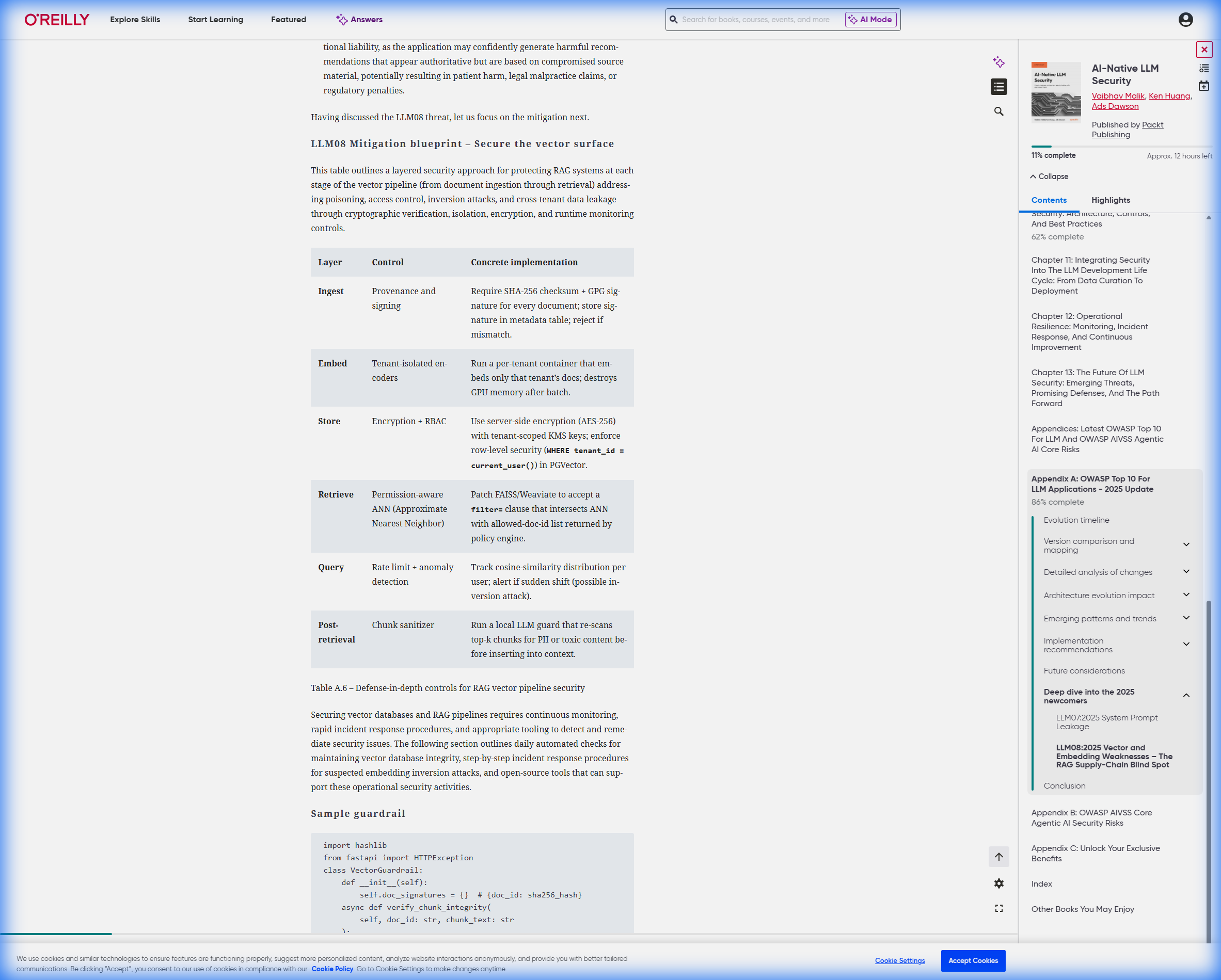
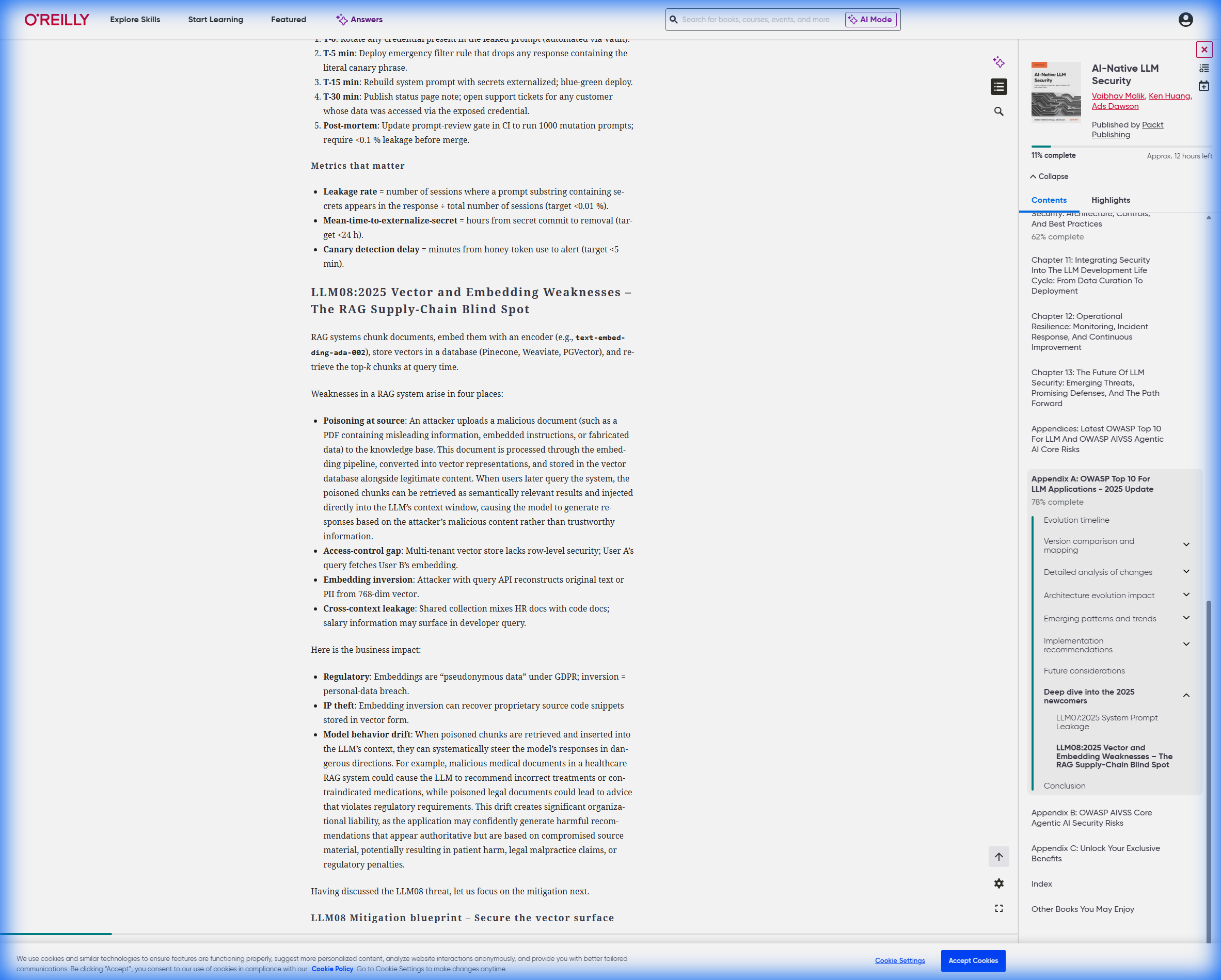
2.2 RAG特定威胁与防御(OWASP LLM08:2025)
根据《AI-Native LLM Security》附录A的OWASP Top 10 for LLM Applications - 2025更新,RAG系统面临特定威胁:
[!CAUTION] LLM08:2025 - Vector and Embedding Weaknesses(向量与嵌入漏洞) RAG系统的”供应链盲点”,攻击者可能通过污染向量数据库实现数据投毒。
防御蓝图:
- 摄入安全
- 对所有文档进行SHA-256校验和验证
- GPG签名验证文档来源
- 检索后消毒
- 部署本地”LLM守卫”重新扫描top-k检索结果
- 在插入上下文前再次检测PII和恶意指令
- 异常检测
- 监控余弦相似度分布
- 检测”嵌入反演攻击”(从向量还原原始文本)
三、企业级安全架构模式
3.1 防御纵深架构图
graph TB
subgraph "用户层"
U[用户查询]
end
subgraph "安全网关层"
A[API网关]
B[速率限制]
C[身份验证]
end
subgraph "应用层(零信任边界内)"
D[查询验证]
E[RBAC权限检查]
F[向量检索]
G[PII脱敏]
H[上下文压缩]
I[输入护栏]
end
subgraph "数据层(本地)"
J[(向量数据库)]
K[(文档存储)]
end
subgraph "外部API层(零信任边界外)"
L[TLS 1.3加密通道]
M[外部SaaS LLM API]
end
subgraph "响应处理层"
N[输出护栏]
O[审计日志]
P[响应过滤]
end
U --> A --> B --> C --> D
D --> E --> F
F --> J
F --> K
F --> G --> H --> I --> L --> M
M --> N --> O --> P --> U
style J fill:#d4edda
style K fill:#d4edda
style M fill:#f8d7da
style L fill:#fff3cd
关键设计原则:
- ✅ 本地优先:敏感数据(原始文档、完整向量)永不离开企业边界
- ✅ 最小暴露:仅发送经脱敏的、最小化的上下文片段
- ✅ 零信任验证:假设每个请求都不可信,逐层验证
- ✅ 可审计性:完整的数据谱系追踪
3.2 SaaS API vs. 自托管LLM对比
| 维度 | SaaS API(如OpenAI/Claude) | 自托管开源模型(Llama/Mistral) |
|---|---|---|
| 部署难度 | ⭐ 极简单 | ⭐⭐⭐⭐ 需要GPU基础设施 |
| 数据控制 | ⚠️ 需信任提供商 | ✅ 100%本地控制 |
| 合规性 | ⚠️ 可能违反GDPR/HIPAA | ✅ 满足严格合规要求 |
| 成本 | 按Token计费(可预测) | 高昂的前期投资+运维成本 |
| 模型性能 | ✅ 最先进(GPT-4/Claude 3.5) | ⚠️ 性能稍逊(但快速改进中) |
| 推荐场景 | 一般企业场景 + 多层安全防护 | 金融/医疗/政府等高安全场景 |
[!TIP] 混合部署策略:使用自托管模型处理高敏感查询,SaaS API处理一般性查询,通过分类器自动路由。
四、实施最佳实践清单
4.1 设计阶段
- 威胁建模:使用STRIDE框架分析RAG管道的每个组件
- 数据分类:标记所有文档的敏感级别(Public/Internal/Confidential/Restricted)
- 选择合规的向量数据库:如Weaviate(支持RLS)、Pinecone(支持命名空间隔离)
4.2 开发阶段
- 集成PII检测库:如Microsoft Presidio、AWS Comprehend
- 实现上下文压缩:使用LLMLingua或自定义摘要模型
- 部署护栏组件:集成Lakera Guard、Hugging Face安全分类器
- 配置审计日志:记录每次检索和生成事件
4.3 运维阶段
- 红队测试:定期尝试绕过安全控制(如提示词注入攻击)
- 监控异常:设置余弦相似度分布、PII检测率等指标的告警
- 定期审查SLA:确保SaaS提供商的数据处理协议符合合规要求
- 密钥轮换:每90天更换API密钥
4.4 合规阶段
- GDPR遵从:实现”被遗忘权”(从向量数据库删除用户数据)
- SOC2审计:提供完整的数据流图和访问日志
- HIPAA合规:对医疗数据使用加密向量数据库(如PGVector + 透明数据加密)
五、核心结论与建议
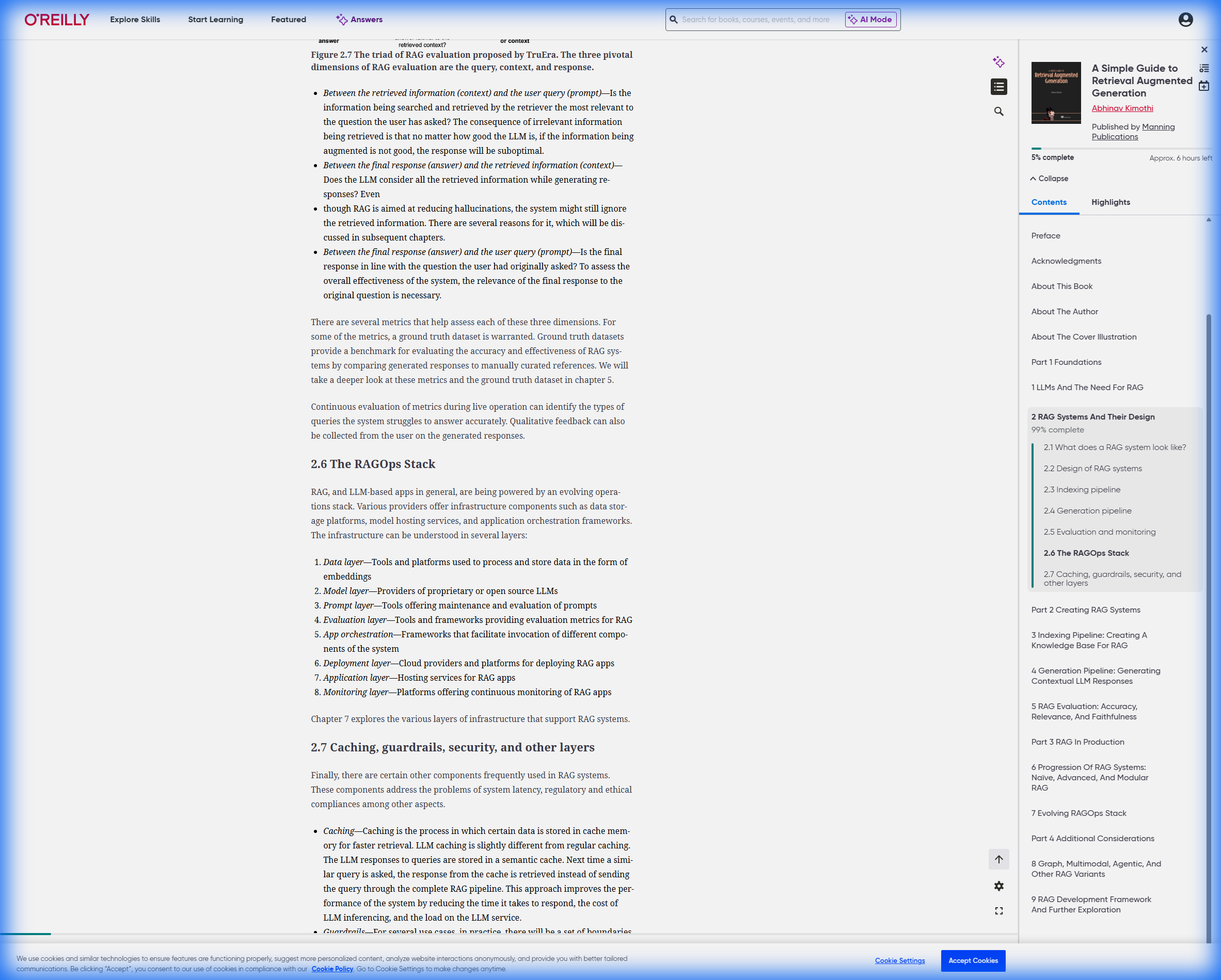
5.1 核心结论
- RAG架构本质上是安全的
- 敏感原始数据永远留在企业本地向量数据库中
- 外部LLM API仅接收经过多层过滤的、最小化的上下文片段
- 这与直接将文档上传到ChatGPT的”简单粘贴”方式有本质区别
- 安全不是单点技术,而是分层防御
- 没有任何单一机制能保证100%安全
- 需要在查询验证、权限控制、数据脱敏、传输加密、输出过滤等5个层次同时设防
- SaaS API可以安全使用,但需要条件
- ✅ 适用场景:一般商业场景 + 完善的脱敏机制
- ❌ 不适用:绝密政府数据、未加密医疗记录、金融交易明细
- ⚠️ 中间地带:通过强力脱敏+合同保障(如OpenAI的企业数据保留政策)
5.2 实施建议
针对不同场景的推荐方案
场景1:初创公司/一般企业(低-中敏感度数据)
1
2
3
4
5
推荐方案:SaaS API + 基础防护
- 使用OpenAI/Anthropic等商用API
- 实施PII脱敏(Presidio)
- 配置基本RBAC
- 预算:低(按Token付费)
场景2:中型企业(中-高敏感度数据)
1
2
3
4
5
推荐方案:混合部署
- 敏感查询 → 自托管Llama 3
- 一般查询 → SaaS API
- 完整的5层防护体系
- 预算:中(需要3-5张A100 GPU)
场景3:金融/医疗/政府(高敏感度数据)
1
2
3
4
5
6
推荐方案:完全自托管
- 所有LLM推理在私有VPC内完成
- 使用加密向量数据库
- 实施零信任网络架构
- 通过SOC2/HIPAA审计
- 预算:高(专用GPU集群+安全团队)
5.3 技术路线图
gantt
title RAG安全实施路线图
dateFormat YYYY-MM-DD
section 基础阶段
PII脱敏集成 :2024-01-01, 30d
RBAC权限系统 :2024-01-15, 30d
section 强化阶段
输入输出护栏 :2024-02-01, 45d
审计日志系统 :2024-02-15, 30d
section 高级阶段
差分隐私实现 :2024-03-01, 60d
自托管LLM部署 :2024-03-15, 90d
section 持续运营
红队测试 :2024-06-01, 14d
季度安全审查 :2024-06-15, 7d
六、参考资料
本研究报告基于以下O’Reilly专业书籍:
- 《Mastering Retrieval-Augmented Generation》 by Ranajoy Bose
- 企业级RAG架构模式
- 微服务分解与安全代理模式
- 《Retrieval-Augmented Generation in Production with Haystack》 by Skanda Vivek
- 生产环境部署最佳实践
- OWASP Top 10 for LLMs应用
- 《AI-Native LLM Security》 by Vaibhav Malik (Packt, Dec 2025)
- OWASP LLM应用安全2025更新
- RAG特定威胁(LLM08: Vector and Embedding Weaknesses)
- 零信任架构与防御纵深
- 《A Simple Guide to Retrieval Augmented Generation》 by Abhinav Kimothi
- RAG基础架构与数据流
- 安全层与护栏机制
附录:研究过程截图
A. RAG基础架构图
B. 索引管道详解
C. OWASP LLM08安全防护
总结陈述
RAG系统通过架构设计本身实现了数据安全与AI能力的平衡。
关键在于理解:RAG不是将数据”发送”给外部API,而是将数据”留在本地”,仅将经过严格过滤和最小化的上下文片段提供给LLM。 这种设计配合PII脱敏、权限控制、加密传输等多层防护,使得即使使用公网SaaS API,也能达到企业级安全标准。
对于更高安全要求的场景,完全可以通过自托管开源模型实现零数据外泄,这正是RAG架构灵活性的体现:安全级别可根据业务需求调节,而不是非黑即白的选择。
报告时间:2026-01-13
研究方法:基于O’Reilly Learning平台权威书籍的系统性文献研究
