这是 DeepMind Scaling Book 系列的第 0 部分。
如何扩展你的模型 (How to Scale Your Model)
LLM 的系统观 (A Systems View of LLMs) (Part 0: Intro | Part 1: Rooflines)
深度学习的大部分内容归根结底仍然像是一种“黑魔法”,但优化模型的性能并不一定如此——即使是在巨大的规模下!相对简单的原理放之四海而皆准——从处理单个加速器到成千上万个——理解它们能让你做许多有用的事情:
- 粗略估计你的模型各个部分距离理论最优值有多近。
- 在不同规模下对不同的并行化方案(如何在多个设备上拆分计算)做出明智的选择。
- 估算训练和运行大型 Transformer 模型所需的成本和时间。
- 设计能利用特定 硬件 特性的算法。
- 基于对当前算法性能瓶颈的明确理解来设计硬件。
预期背景知识 (Expected background):我们假设你对 LLM 和 Transformer 架构有基本的了解,但不一定了解它们在大规模下是如何运行的。你应该通过了解 LLM 训练的基础知识,最好对 JAX 有一些基本的熟悉。如果你需要补充背景知识,这篇关于 Transformer 架构的博客文章 和 原始 Transformer 论文 可能会有所帮助。另外,请查看 此列表 以获取更多有用的并行阅读和后续阅读材料。
目标与反馈 (Goals & Feedback):读完本书,你应该能够自如地为给定硬件平台上的 Transformer 模型估算最佳并行化方案,并大致了解训练和推理需要多长时间。如果你做不到,请发邮件给我们或通过 Pull Request 留言!我们很乐意知道如何让这部分内容更清晰。
你可能还会喜欢阅读关于 NVIDIA GPU 的新章节 第12章!
为什么要关心这个? (Why should you care?)
三四年前,我认为大多数 ML 研究人员都不需要理解本书中的任何内容。但今天,即使是“小”模型也运行在如此接近硬件极限的地方,以至于做新颖的研究需要你思考规模下的效率1。如果在 Roofline 效率上付出了 20% 的代价,那么在基准测试中获得 20% 的提升也是无关紧要的。 有前途的模型架构经常因为无法在大规模下高效运行,或者没人投入精力让它们高效运行而失败。
“模型扩展 (Model Scaling)”的目标是能够增加用于训练或推理的芯片数量,同时实现吞吐量的成比例、线性增加。 这被称为“强扩展 (strong scaling)”。虽然增加额外的芯片(“并行化”)通常会减少计算时间,但它也带来了芯片间通信增加的成本。当通信时间超过计算时间时,我们就变成了“通信受限 (communication bound)”,无法进行强扩展2。如果我们对硬件有足够的了解,能够预测这些瓶颈将在哪里出现,我们就可以设计或重新配置我们的模型来避免它们3。
我们在本书中的目标是解释 TPU (和 GPU) 硬件是如何工作的,以及 Transformer 架构是如何演变为在当前硬件上表现良好的。我们希望这对设计新架构的研究人员和致力于让当前一代 LLM 运行得更快的工程师都有用。
高层大纲 (High-Level Outline)
全书的整体结构如下:
第 1 章 解释 Roofline 分析以及哪些因素会限制我们的扩展能力(通信、计算和内存)。第 2 章 和 第 3 章 详细讨论了 TPU 是如何工作的,既作为单个芯片,也作为具有有限带宽和延迟的互连链路的互连系统——这点至关重要。我们将回答如下问题:
- 特定大小的矩阵乘法应该花费多长时间?在什么点上它受限于计算、内存或通信带宽?
- TPU 是如何连接在一起形成训练集群的?系统的每个部分有多少带宽?
- 在多个 TPU 之间 gather, scatter 或重新分发数组需要多长时间?
- 我们如何高效地通过在设备上以不同方式分布的矩阵进行乘法运算?
 Figure: 来自 第 2 章 的图表,展示了 TPU 如何执行逐元素乘积。根据我们数组的大小和各种链路的带宽,我们可能会发现自己处于计算受限(使用全部硬件计算能力)或通信受限(受限于内存加载)的状态。
Figure: 来自 第 2 章 的图表,展示了 TPU 如何执行逐元素乘积。根据我们数组的大小和各种链路的带宽,我们可能会发现自己处于计算受限(使用全部硬件计算能力)或通信受限(受限于内存加载)的状态。
五年前,ML 拥有丰富多彩的架构景观——ConvNets, LSTMs, MLPs, Transformers——但现在我们主要只有 Transformer。我们坚信值得理解 Transformer 架构的每一个部分:每个矩阵的确切大小,归一化发生在哪里,每个部分有多少参数和 FLOPs 4。第 4 章 仔细梳理了这种“Transformer 数学”,展示了如何计算训练和推理的参数和 FLOPs。这告诉我们模型将使用多少内存,我们将花费多少时间在计算或通信上,以及 Attention 何时相对于前馈块变得重要。
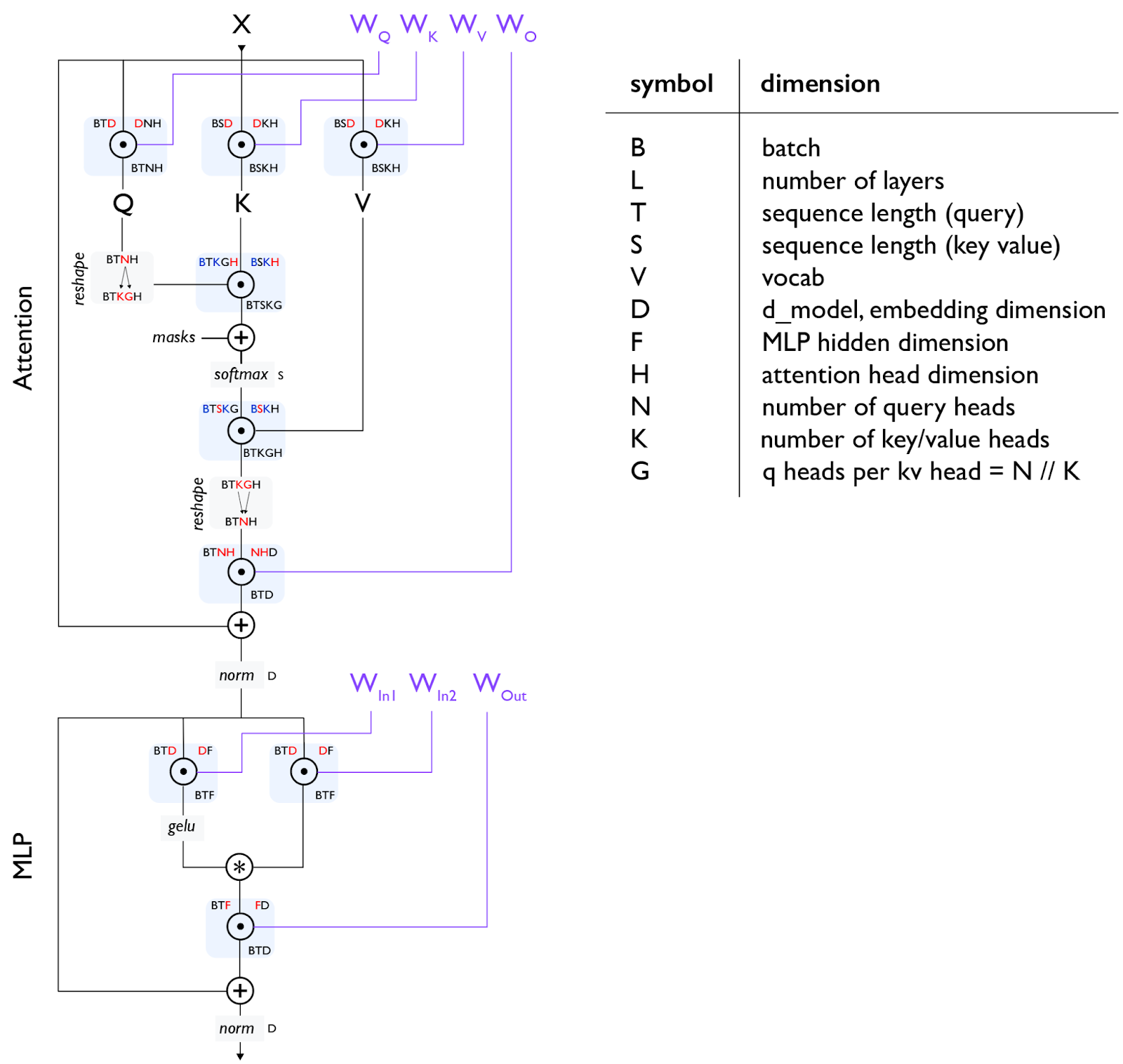 Figure: 一个标准的 Transformer 层,每个矩阵乘法 (matmul) 显示为圆圈内的一个点。所有参数(不包括 norms)显示为紫色。第 4 章 将更详细地通过此图进行讲解。
Figure: 一个标准的 Transformer 层,每个矩阵乘法 (matmul) 显示为圆圈内的一个点。所有参数(不包括 norms)显示为紫色。第 4 章 将更详细地通过此图进行讲解。
第 5 章:训练 和 第 7 章:推理 是本书的核心,我们在其中讨论基本问题:给定某个大小的模型和一定数量的芯片,我如何并行化我的模型以保持在“强扩展”范围内?这是一个令人惊讶的复杂问题。在高层次上,有 4 种主要的并行化技术用于将模型拆分到多个芯片上(数据、张量、流水线 和 专家),以及许多其他减少内存需求的技术(重计算 (rematerialisation)、优化器/模型分片 (aka ZeRO)、主机卸载 (host offload)、梯度累积 (gradient accumulation))。我们在这里讨论其中许多技术。
我们希望在这些章节结束时,你能够通过自己为新架构或设置选择它们。第 6 章 和 第 8 章 是实用教程,将这些概念应用于 LLaMA-3,这是一个流行的开源模型。
最后,第 9 章 和 第 10 章 看看如何在 JAX 中实现其中一些想法,以及当事情出错时如何分析和调试你的代码。第 12 章 是一个新的部分,也深入探讨了 GPU。
自始至终,我们都试图给你一些问题让你自己去解决。请不要有压力去阅读所有章节或按顺序阅读。请留下反馈。目前,这是一个草稿,并将继续修订。谢谢!
我们要感谢 James Bradbury 和 Blake Hechtman,本文档中的许多想法都源于他们。
话不多说,这里是第 1 节,关于 TPU Rooflines。
章节链接 (Links to Sections)
这系列文章可能比需要的要长,但我们希望这不会吓到你。前三章是预备知识,如果熟悉可以跳过,尽管它们介绍了后面使用的符号。最后三个部分可能是最实用的,因为它们解释了如何处理真实模型。
Part 1: 预备知识 (Preliminaries)
- Chapter 1: Roofline 分析简介. 算法受限于三件事:计算、通信和内存。我们可以用这些来近似我们的算法运行得有多快。
- Chapter 2: 如何思考 TPU. TPU 是如何工作的?这如何影响我们可以训练和服务哪些模型?
- Chapter 3: 分片矩阵及其乘法. 在这里,我们通过我们最喜欢的操作:(分片)矩阵乘法,来解释模型分片和多 TPU 并行性。
Part 2: Transformers
- Chapter 4: 你需要知道的所有 Transformer 数学. Transformer 在其前向和后向传递中使用多少 FLOPs?你能计算参数的数量吗?它的 KV缓存的大小?我们在这里通过数学计算来解决这个问题。
- Chapter 5: 如何为训练并行化 Transformer. FSDP. Megatron 分片. 流水线并行. 给定一定数量的芯片,我如何尽可能高效地以此 batch size 训练给定大小的模型?
- Chapter 6: TPU 上的 LLaMA 3 训练. 我们将如何在 TPU 上训练 LLaMA 3?需要多长时间?成本是多少?
- Chapter 7: 关于 Transformer 推理的一切. 一旦我们训练了一个模型,我们就必须服务它。推理增加了一个新的考虑因素——延迟——并改变了内存格局。我们将讨论解耦服务是如何工作的以及如何思考 KV 缓存。
- Chapter 8: TPU 上的 LLaMA 3 服务. 在 TPU v5e 上服务 LLaMA 3 需要多少成本?延迟/吞吐量的权衡是什么?
Part 3: 实战教程 (Practical Tutorials)
- Chapter 9: 如何分析 TPU 代码. 真实的 LLM 永远不会像上面的理论那样简单。在这里,我们要解释 JAX + XLA 栈以及如何使用 JAX/TensorBoard 分析器来调试和修复实际问题。
- Chapter 10: 在 JAX 中对 TPU 编程. JAX 提供了一堆用于并行计算的神奇 API,但你需要知道如何使用它们。有趣的例子和练习题。
Part 4: 总结与额外内容 (Conclusions and Bonus Content)
- Chapter 11: 总结与延伸阅读.关于 TPU 和 LLM 的结语和延伸阅读。
- Chapter 12: 如何思考 GPU. 关于 GPU 的额外部分,它们如何工作,如何联网,以及它们的 Roofline 与 TPU 有何不同。
脚注
引用
在学术背景下引用时,请按如下方式引用本作品:
1
Austin et al., "How to Scale Your Model", Google DeepMind, online, 2025.
或者作为 BibTeX 条目:
1
2
3
4
5
6
7
8
@article{scaling-book,
title = {How to Scale Your Model},
author = {Austin, Jacob and Douglas, Sholto and Frostig, Roy and Levskaya, Anselm and Chen, Charlie and Vikram, Sharad and Lebron, Federico and Choy, Peter and Ramasesh, Vinay and Webson, Albert and Pope, Reiner},
publisher = {Google DeepMind},
howpublished = {Online},
note = {Retrieved from https://jax-ml.github.io/scaling-book/},
year = {2025}
}
-
从历史上看,ML 研究遵循着系统创新和软件改进之间的某种 tick-tock 周期。Alex Krizhevsky 不得不编写可怕的 CUDA 代码来让 CNN 变快,但几年后,像 Theano 和 TensorFlow 这样的库意味着你不再需要这样做。也许这也会发生在这里,这本书中的所有内容在几年后都会被抽象掉。但是扩展定律已将我们的模型推向了硬件的最前沿,而且似乎很可能,在可预见的未来,做前沿研究将与理解如何有效地将模型扩展到大型硬件拓扑有着千丝万缕的联系。 ↩︎
-
随着计算时间的减少,你通常也会在单个芯片的层面上遇到瓶颈。你闪亮的新 TPU 或 GPU 可能被评级为每秒执行 500 万亿次操作,但如果你不小心,如果它被在内存中移动参数所拖累,它很容易只能做到其中的十分之一。单芯片计算、内存带宽和总内存的相互作用对于扩展故事至关重要。 ↩︎
-
硬件设计师面临着相反的问题:构建硬件,为我们的算法提供足够的计算、带宽和内存,同时最大限度地降低成本。你可以想象这种“协同设计”问题有多么令人紧张:你必须押注于当第一批芯片真正上市时(通常是 2 到 3 年后),算法会是什么样子。TPU 的故事是这场博弈中的一个响亮成功。矩阵乘法是一种独特的算法,因为它使用的每字节内存 FLOPs 比几乎任何其他算法都多(N FLOPs/byte),早期的 TPU 及其脉动阵列架构实现了比当时制造的 GPU 更好的 perf/$。TPU 是为 ML 工作负载设计的,而带有 TensorCores 的 GPU 正在迅速改变以填补这一利基市场。但是你可以想象,如果神经网络没有腾飞,或者以某种 TPU(本质上比 GPU 更不灵活)无法处理的根本方式发生了变化,那代价会有多大。 ↩︎
-
浮点运算 (FLoating point OPs),基本上是所需的加法和乘法的总数。虽然许多来源将 FLOPs 理解为“每秒操作数”,但我们使用 FLOPs/s 来明确表示这一点。 ↩︎
