这是 DeepMind Scaling Book 系列的第 1 部分。
关于 Rooflines 的一切 (All About Rooflines)
How To Scale Your Model Part 1 (Part 0: Introduction | Part 2: TPUs)
当我们在硬件上运行算法时,我们受到三件事的限制:我们的计算机做数学运算的速度有多快 (OPs/second),移动数据的可用带宽 (bytes/second),以及存储数据的总内存 (bytes)。这些“Roofline (屋顶线)”约束让我们能够对给定计算的时间设定上限和下限。
时间都去哪儿了? (Where Does the Time Go?)
让我们从一个极其简单的问题开始:为什么一个算法需要 50ms 而不是 50s 或 5ms? 模型内部实际发生了什么需要大量时间的操作,我们应该预期它花费多长时间?
计算 (Computation):深度学习模型实际上是一堆矩阵乘法,每个都由浮点乘法和加法“操作” (FLOPs) 组成。我们的加速器速度决定了这些计算需要多长时间:
\[T_{math} = \frac{\text{Computation FLOPs}}{\text{Accelerator FLOPs/s}}\]例如,一个 NVIDIA H100 可以执行大约 $9.89 \times 10^{14}$ bfloat161 FLOPs/s,而一个 TPU v6e 可以执行 $9.1 \times 10^{14}$ FLOPs/s2。这意味着在 H100 上做 $10^{12}$ FLOPs 大约需要 $10^{12} / 9.89 \times 10^{14} = 1.01\text{ms}$,而在 TPU v6e 上需要 $10^{12} / 9.1 \times 10^{14} = 1.1\text{ms}$3。
芯片内通信 (Communication within a chip):在加速器内部,张量需要在片上内存 (HBM) 和计算核心之间传输。你会看到这个链路的带宽被称为“HBM 带宽”4。在 H100 上,这大约是 3.35TB/s,在 TPU v6e 上 这大约是 1.6TB/s。
芯片间通信 (Communication between chips):当我们跨多个加速器分布模型时,张量经常需要在它们之间传输。我们的硬件上通常有几种选择(ICI, DCN 和 PCIe),每种都有不同的带宽。
无论是芯片内还是芯片间通信,我们都以 bytes/s 为单位进行测量,并估算总通信时间:
\[T_{comms} = \frac{\text{Communication Bytes}}{\text{Network/Memory Bandwidth Bytes/s}}\]通常(但并不总是),单芯片内的计算可以与芯片内和芯片间的通信重叠。这意味着 我们可以通过使用计算和通信时间的最大值来为训练和推理时间设定下限。我们也 可以用它们的总和来设定上限。在实践中,我们针对最大值进行优化,因为代数更简单,而且我们通常可以通过重叠通信和计算来接近这个界限。如果我们以最大值为目标进行优化,那么下限和上限相差最多 2 倍,因为 $T_{math} + T_{comms} \leq 2 * \max(T_{math}, T_{comms})$。这之后我们通过建模“重叠区域”和开销来进一步提高准确性,这可以通过分析特定模型和目标系统来获知。
\[T_{lower}=\max(T_{math}, T_{comms})\] \[T_{upper} = T_{math} + T_{comms}\]如果我们假设我们可以完美地重叠通信和计算,当 $T_{math} > T_{comms}$ 时,我们会看到硬件的完全利用。我们称之为“计算受限 (compute-bound)”。当 $T_{comms} > T_{math}$ 时,我们倾向于“通信受限 (communication-bound)”,加速器的 FLOPs/s 至少有一部分浪费在等待数据传递上。判断一个操作是计算受限还是通信受限的一种方法是查看其“算术强度 (arithmetic intensity)”或“运算强度 (operational intensity)”。
定义:一个算法的算术强度是它执行的总 FLOPs 与它需要通信的字节数之比——无论是在芯片内还是芯片间。
\[\text{Arithmetic Intensity} = \frac{\text{Computation FLOPs}}{\text{Communication Bytes}}\]算术强度衡量给定操作的“FLOPs per byte”。在一阶近似下,当我们的算术强度高时,$T_{math}$ 比 $T_{comms}$ 大,我们通常使用大部分可用的 FLOPs。当相反的情况发生时,我们在通信上花费更多时间并浪费 FLOPs。这种交叉发生点是我们硬件的“峰值算术强度”,即峰值加速器 FLOPs/s 与加速器带宽的比率。
\[\begin{align*} T_{math} > T_{comms} \Leftrightarrow \frac{\text{Computation FLOPs}} {\text{Accelerator FLOPs/s}} > \frac{\text{Communication Bytes}}{\text{Bandwidth Bytes/s}} & \\[0.5em] \Leftrightarrow \frac{\text{Computation FLOPs}}{\text{Communication Bytes}} > \frac{\text{Accelerator FLOPs/s}}{\text{Bandwidth Bytes/s}} & \\[0.5em] \Leftrightarrow \text{Intensity}(\text{Computation}) > \text{Intensity}(\text{Accelerator}) & \\ \end{align*}\]量 $\text{Intensity}(\text{Accelerator})$ 是我们的加速器达到其峰值 FLOPs/s 时的算术强度。对于 TPU v5e MXU,这大约是 240 FLOPs/byte,因为 TPU 可以执行 1.97e14 FLOPs/s 并从 HBM 加载 8.2e11 bytes/s5。这意味着如果一个算法的算术强度低于 240 FLOPs/byte,它将受到字节加载的限制,因此我们将无法很好地利用我们的硬件6。让我们看一个这样的例子:
例子 (点积):计算两个 bfloat16 精度向量的点积,x • y: bf16[N], bf16[N] → bf16[1],我们需要从内存加载 $x$ 和 $y$,每个有 $2 * N = 2N$ 字节,执行 $N$ 次乘法和 $N-1$ 次加法,并将 $2$ 字节写回 HBM。
当 $N \rightarrow \infty$ 时。所以点积的算术强度是 $\frac{1}{2}$,或者换句话说,点积每加载一个字节执行 0.5 次浮点运算。这意味着我们的算术强度低于我们的硬件,我们将是通信受限的7。
可视化 Rooflines (Visualizing rooflines)
我们可以使用 Roofline 图 来可视化内存和计算之间的权衡,该图绘制了算法在我们硬件上的峰值可实现 FLOPs/s(吞吐量,y轴)与该算法的算术强度(x轴)的关系。这是一个对数-对数图的例子:
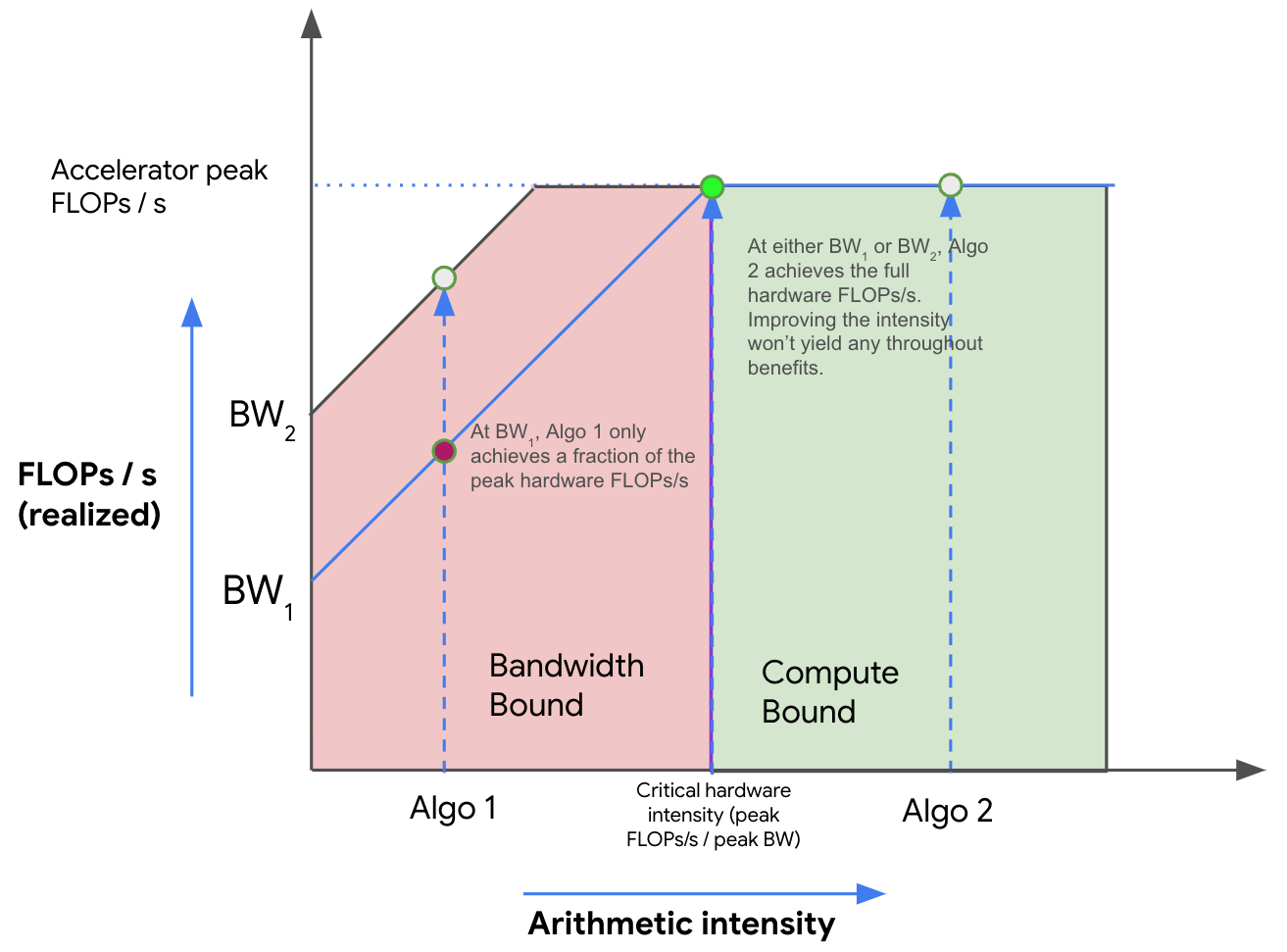 Figure: 一个示例 Roofline 图,显示了两个具有不同算术强度的算法(Algo 1 和 Algo 2)以及它们在不同带宽(BW1 和 BW2)下对应的理论峰值吞吐量。在红色区域中,算法在两种带宽下都是带宽受限的,并且浪费了一部分硬件的峰值 FLOPs/s。黄色区域仅在较低带宽 (BW1) 下是带宽受限的。绿色区域在所有带宽下都是计算受限的。在这里,我们使用的是加速器的峰值 FLOPs/s,增加带宽或提高强度没有任何好处。
Figure: 一个示例 Roofline 图,显示了两个具有不同算术强度的算法(Algo 1 和 Algo 2)以及它们在不同带宽(BW1 和 BW2)下对应的理论峰值吞吐量。在红色区域中,算法在两种带宽下都是带宽受限的,并且浪费了一部分硬件的峰值 FLOPs/s。黄色区域仅在较低带宽 (BW1) 下是带宽受限的。绿色区域在所有带宽下都是计算受限的。在这里,我们使用的是加速器的峰值 FLOPs/s,增加带宽或提高强度没有任何好处。
如上所述,随着强度增加(从左到右移动),我们最初看到算法性能(以 FLOPs/s 为单位)线性增加,直到我们达到硬件的临界算术强度(TPU v5e 为 240)。任何强度较低的算法都将是带宽 (BW) 受限的,并受到峰值内存带宽的限制(以红色显示)。任何在右侧的算法都将充分利用我们的 FLOPs(以绿色显示)。在这里,Algo 1 是通信受限的,仅使用了总硬件 FLOPs/s 的一小部分。Algo 2 是计算受限的。我们通常可以通过增加其算术强度或增加可用内存带宽(从 BW1 移动到 BW2)来提高算法的性能。
矩阵乘法 (Matrix multiplication)
让我们看看我们即将成为最喜欢的算法:矩阵乘法 (aka matmul)。我们写 $X * Y \rightarrow Z$,其中 $X$ 的形状为 $\text{bf16}[B, D]$,$Y$ 的形状为 $\text{bf16}[D, F]$,$Z$ 的形状为 $\text{bf16}[B, F]$。要做这个 matmul,我们需要加载 $2DF + 2BD$ 字节,执行 $2BDF$ FLOPs,并将 $2BF$ 字节写回8。9 因此:
\[\text{Intensity}(\text{matmul}) = \frac{2BDF}{2BD + 2DF + 2BF} = \frac{BDF}{BD + DF + BF}\]如果我们假设“batch size” $B$ 相对于 $D$ 和 $F$ 很小,我们可以得到一个很好的简化。那么我们得到:
\[\frac{BDF}{BD + DF + BF} \approxeq \frac{BDF}{DF} = B\] \[\text{Intensity}(\text{matmul}) > \text{Intensity}(\text{TPU}) \implies B > \frac{1.97e14}{8.20e11} = 240\]这对于 Transformer matmuls 来说是一个合理的假设,因为我们通常有一个本地(每副本)batch size $B < 1024$ tokens(不是序列),但 $D$ 和 $F > 8000$。因此,当我们的每副本10 batch size 大于 240 tokens 时,我们通常会变得计算受限,这是一个非常简单的规则!
要点 (Takeaway): 为了让 bfloat16 matmul 在大多数 TPU 上计算受限,我们需要每副本 token batch size 大于 240。11
这带有一些值得注意的警告,我们将在下面的问题中探讨,特别是关于量化(例如,如果我们量化激活但仍然做全精度 FLOPs),但这是一个需要记住的好规则。对于 GPU,这个数字稍高(接近 300),但同样的结论通常也是成立的。当我们将大 matmul 分解为小 matmuls 时,tile 大小也很重要12。我们将在下一节讨论更底层的 GPU 和 TPU 细节。
网络通信 Rooflines (Network communication rooflines)
到目前为止,我们讨论的所有 rooflines 都是内存带宽 rooflines,全部在单个芯片内。这不应该被视为规则。事实上,我们在本书中关心的大多数 rooflines 涉及芯片间的通信:通常是涉及跨多个 TPU 分片的矩阵的矩阵乘法。
举一个稍微做作的例子,假设我们要乘以两个大矩阵 $X\sim \text{bfloat16[B, D]}$ 和 $Y \sim \text{bfloat16[D, F]}$,它们均匀地分布在 2 个 TPU/GPU 上(沿 $D$ 维度)。要做这个乘法(我们将在第 3 章中看到),我们可以将每个 TPU 上的一半矩阵相乘(TPU 0 上 A = X[:, :D // 2] @ Y[:D // 2, :],TPU 1 上 B = X[:, D // 2:] @ Y[D // 2:, :]),然后将生成的“部分和”复制到另一个 TPU 并将它们相加。假设我们可以在每个方向复制 4.5e10 字节,并在每个芯片上执行 1.97e14 FLOPs/s。$T_{math}$ 和 $T_{comms}$ 是多少?
$T_{math}$ 显然是之前的一半,因为每个 TPU 做一半的工作,即13
\[T_{math} = \frac{2BDF}{2 \cdot \text{Accelerator FLOPs/s}} = \frac{BDF}{1.97e14}\]现在 $T_{comms}$ 呢?这现在指的是芯片间的通信时间!这只是发送的总字节数除以网络带宽,即
\[T_{comms} = \frac{2BF}{\text{Network Bandwidth}} = \frac{2BF}{4.5e10}\]因此,当以下情况时我们变得计算受限(现在是相对于芯片间网络):
\[\text{Intensity}(\text{matmul (2-chips)}) > \text{Intensity}(\text{TPU w.r.t. inter-chip network})\]或者等价地当 $\frac{BDF}{2BF} = \frac{D}{2} > \frac{1.97e14}{4.5e10} = 4377$ 或 $D > 8755$ 时。注意,与之前不同,临界阈值现在取决于 $D$ 而不是 $B$!试着想一想为什么会这样。这只是一个这样的例子,但我们强调这种 roofline 对于知道何时可以将操作并行化到多个 TPU 至关重要。
一些练习题 (A Few Problems to Work)
问题 1 [int8 matmul]: 假设我们想用 int8 精度(每个参数 1 字节)而不是 bfloat16 做 matmul $X[B, D] \cdot_D Y[D, F] \rightarrow Z[B, F]$。14
- 需要从内存加载多少字节?有多少需要写回内存?
- 执行了多少总 OPs?
- 算术强度是多少?
- $T_{math}$ 和 $T_{comms}$ 的 roofline 估计是多少?整个操作运行时间的合理上下限是多少?
假设我们的 HBM 带宽是 8.1e11 bytes/s,int8 峰值 OPs/s 是 3.94e14(大约是 bfloat16 的 2 倍)。
点击这里查看答案。
- 因为我们用 int8 存储参数,每个参数 1 字节,所以我们有 \(BD + DF\) 字节从 HBM 加载,\(BF\) 写回。
- 这和 bfloat16 一样,但理论上 int8 OPs/s 应该更快。所以这仍然是 $2BDF$ FLOPs。
- 算术强度是 \(2BDF / (BD + DF + BF)\)。如果我们做同样的假设 \(B \ll D\) 和 \(B \ll F\),我们得到算术强度为 \(2B\),意味着我们的规则变成了 $B > \text{HBM int8 arithmetic intensity} / 2$。使用给出的数字,这个 int8 强度是
3.94e14 / 8.1e11 = 486,所以规则是 $B > 486 / 2 = 243$。注意这基本上没变! - \(T_{math} = 2BDF / 3.94e14\) 且 \(T_{comms} = (BD + DF + BF) / 8.1e11\),所以一个合理的下限是 \(\max(T_{math}, T_{comms})\) 而上限是 \(T_{math} + T_{comms}\)。
问题 2 [int8 + bf16 matmul]: 在实践中,我们经常对权重与激活进行不同的量化,所以我们可能会以非常低的精度存储权重,但保持激活(和计算)在更高精度。假设我们想将权重量化为 int8 但保持激活(和计算)在 bfloat16。我们在什么 batch size 时变得计算受限?假设 1.97e14 bfloat16 FLOPs/s。
提示:这具体意味着 bfloat16[B, D] * int8[D, F] -> bfloat16[B, F],其中 $B$ 是“batch size”。
点击这里查看答案。
再次假设 B 很小,我们有 2BDF bfloat16 FLOPs 但只有 DF 权重(而不是 bfloat16 中的 2DF)。这意味着当 \(2B > 240\) 或 \(B > 120\) 时我们变得计算受限。这低得多,意味着如果我们能做 int8 权重量化(这也相当容易做)但仍然做 bfloat16 FLOPs,我们在效率上获得了有意义的胜利(尽管 int8 OPs 会更好)。
问题 3: 采用问题 2 的设置,为 $F = D = 4096$ 和 $F = D = 1024$ 绘制峰值 FLOPs/s vs. $B$ 的 roofline 图。使用加载的确切字节数,而不是近似值。
点击这里查看答案。
这是问题中的图:
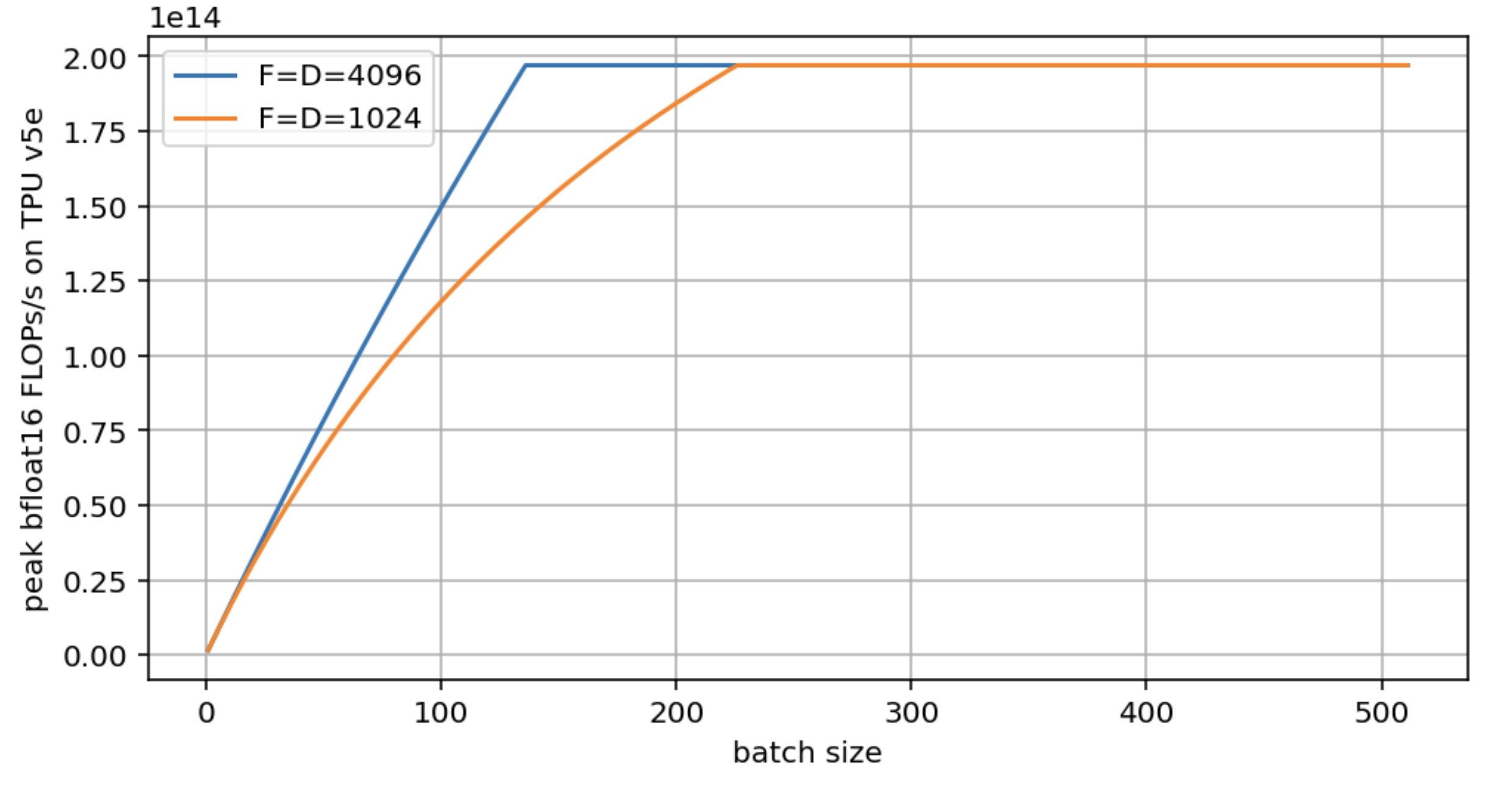
注意,虽然两个模型最终都达到了硬件峰值 FLOPs/s,但较大的 D/F 更快达到。D=F=1024 几乎使临界 batch size 翻倍。生成此图的代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
import matplotlib.pyplot as plt
import numpy as np
bs = np.arange(1, 512)
def roofline(B, D, F):
total_flops = 2*B*D*F
flops_time = total_flops / 1.97e14
comms_time = (2*B*D + D*F + 2*B*F) / 8.2e11
total_time = np.maximum(flops_time, comms_time)
return total_flops / total_time
roofline_big = roofline(bs, 4096, 4096)
roofline_small = roofline(bs, 1024, 1024)
plt.figure(figsize=(8, 4))
plt.plot(bs, roofline_big, label='F=D=4096')
plt.plot(bs, roofline_small, label='F=D=1024')
plt.legend()
plt.xlabel('batch size')
plt.ylabel('peak bfloat16 FLOPs/s on TPU v5e')
plt.grid()
问题 4: 如果我们想执行 $\text{int8[B, D]} *_D \text{int8[B, D, F]} \rightarrow \text{int8[B, F]}$,其中我们想象每个 batch 元素有一个不同的矩阵。这个操作的算术强度是多少?
点击这里查看答案。
让我们从看总 FLOPs 和 comms 开始。
- 总 FLOPs: FLOPs 基本上是一样的,因为我们做相同数量的 \(BD \times DF\) matmuls(这在第 4 章中有更多讨论)。所以这只是 \(2BDF\)。
- 总 comms: 我们这里有更多的 comms: \(BD + BDF + BF\)。
- 因此,我们的算术强度现在实际上是 \(2BDF / (BD + BDF + BF)\)。由于 \(BDF\) 主导分母,这大约是 \(2\)。所以它不再依赖于 batch size,而基本上是常数。这很糟糕,因为这意味着无论如何我们基本上总是通信受限的。
问题 5 [GPU 内存 Rooflines]: 使用 NVIDIA 提供的 H100 规格表,计算矩阵乘法变得计算受限时的 batch size。注意 Tensor Core FLOPs 数字是真实值的两倍,因为它们只有在结构化稀疏性下才能实现。
点击这里查看答案。
从规格表中,我们看到报告的 bfloat16 FLOPs 值是 1.979e15 FLOPs/s,带有一个星号注明 “with sparsity”(带稀疏性)。不仅仅是稀疏性,真实值是这个的一半,意味着接近 1e15 FLOPs/s。内存带宽是 3.35TB/s,或 3.35e12 bytes / second。因此 $B_{crit}$ 是 1e15 / 3.35e12 = 298,与 TPU 相当相似。
Part 1 就到这里!对于 Part 2,看看真实的 TPU 如何处理 FLOPs 和通信,点击这里。
脚注
-
H100 和 B200 通常只能达到声称的峰值 FLOPs 的 80-85% 左右,而 TPU 在正常使用中可以更接近 95%。 ↩︎
-
注意这些芯片的价格不同,此比较并未对成本进行归一化。 ↩︎
-
NVIDIA 也称之为 “memory bandwidth”。 ↩︎
-
MXU 是 TPU 上的矩阵乘法单元。我们在这里说明这一点是因为 TPU 还有其他加速器,如 VPU,负责逐元素操作,它们具有不同的峰值 FLOPs/s。 ↩︎
-
只有当算法从 HBM 加载权重并在 MXU 中运行时,这才是真的。正如我们在下一节将讨论的,我们有时可以将参数存储在具有更高带宽的 VMEM 中。许多算法也在 VPU 中运行,这具有不同的性能特征。 ↩︎
-
上面的 240 数字在这里不是正确的比较,因为正如你在下一节中看到的,点积是在 VPU 上执行的,而不是在 MXU 上。TPU v5p VPU 每秒可以做大约 7e12 FLOPs,所以它的临界强度大约是 3,这意味着我们在这里仍然有些通信受限。无论哪种方式,我们的强度低且恒定的事实意味着在大多数硬件上很难成为计算受限。 ↩︎
-
严格来说,我们执行 $BF \times (2D - 1)$ FLOPs,但这足够接近。这来自 $BDF$ 次乘法和 $BF * (D-1)$ 次加法。第 4 章有更多细节。 ↩︎
-
虽然 matmul 的输出技术上是 float32,但我们在复制回 HBM 之前通常会将其转换为 bfloat16。 ↩︎
-
我们说每副本是因为,如果我们做某种模型分片来增加 matmul 中使用的芯片数量,我们会以相同的量扩展我们的可用计算和内存带宽。因此,对于模型权重的每个独立副本,临界 batch size 是真实的。 ↩︎
-
注意,这不是通常意义上的 batch size(序列 batch size)。事实证明,大多数 rooflines 纯粹取决于 token 的数量,无论它们属于相同还是不同的序列。例如,如果你在 128 个 GPU 上有 512 个序列,每个序列 4096 个 token 的 batch size,你的总 batch size 为
512 * 4096 = 2Mtokens,本地 batch size 为 16k tokens。 ↩︎ -
当我们做一个大矩阵乘法时,我们需要将其分解为更小的 tiles,以适应 VMEM/SMEM/TMEM,即更高带宽的片上内存。这导致我们要多次加载块,所以我们只加载 $O(N^2)$ 字节并不完全正确。考虑一个 $(m, k) \cdot (k, n)$ matmul,tile 大小为 $bm$, $bk$, $bm$。设 $tm = m / bm$ 等。那么总 FLOPs 是 $2 \cdot tm \cdot tn \cdot tk \cdot bm \cdot bn \cdot bk$,总字节数是 $2 \cdot tm \cdot tn \cdot (tk \cdot (bm \cdot bk + bk \cdot bn) + 2 \cdot bm \cdot bn)$。忽略最后一项,我们的强度为 $bm \cdot bn / (bm + bn)$,这与上面相似。 ↩︎
-
我们忽略了将两个部分和相加所需的 FLOPs(另外 DF 次加法),但这基本上可以忽略不计。 ↩︎
-
在这里和整本书中,我们将使用符号 $A \cdot_D B$ 来表示乘法正在对 D 维度执行收缩。这是滥用 einsum 符号。 ↩︎
