Lumerical 与作业调度系统集成 (支持 SGE, Slurm, Torque, LSF)
概述
本指南介绍了如何将 Lumerical CAD 的 Job Manager 与一些常见的作业调度系统(如 SGE、Slurm、Torque 和 IBM LSF)进行集成。 完成这些步骤后,在集群上运行仿真将与在本地计算机上运行一样无缝。 您只需点击“运行”,作业就会自动提交到作业调度系统的队列中(如果需要,文件会自动传输),Lumerical 作业管理器会定期更新仿真的当前状态和进度,完成后,结果会自动加载到您当前的 CAD 会话中。
已知限制
- 作业管理器的“退出但不保存”和“退出并保存”选项目前不受支持。 这适用于单个仿真以及将作业调度器作为资源的参数扫描。
- 点击“强制退出”时,已提交的作业不会被取消,需要手动取消。
- 当使用通过 SSH 进行文件上传和下载功能时,传输状态不会反映在作业管理器的状态视图中。
- 作业管理器窗口在后台下载文件期间将保持打开状态,并在该过程完成后关闭。
要求
- Lumerical Products 2020a R3 (或更新版本)
- Ansys Lumerical 2023 R2.2 (或更新版本) 用于基于用户的配置
- 集群需安装以下任一作业调度系统:Slurm、Torque、LSF、SGE,并配置好 X11 显示以及已安装并配置好许可证服务器的 Lumerical 产品。
- 如果使用 AWS ParallelCluster,请参阅 AWS-ParallelCluster 文档了解详情。
资源配置
-
添加/编辑资源:
- 在 Lumerical CAD 的“资源配置” (Resource Configuration) 界面中,添加或编辑一个新的资源。
- 如果队列已配置为处理可用许可证的数量,则将容量 (Capacity) 设置为 0 (无限);否则,将其设置为许可证服务器上可用的最大求解引擎许可证数量。
-
高级资源设置:
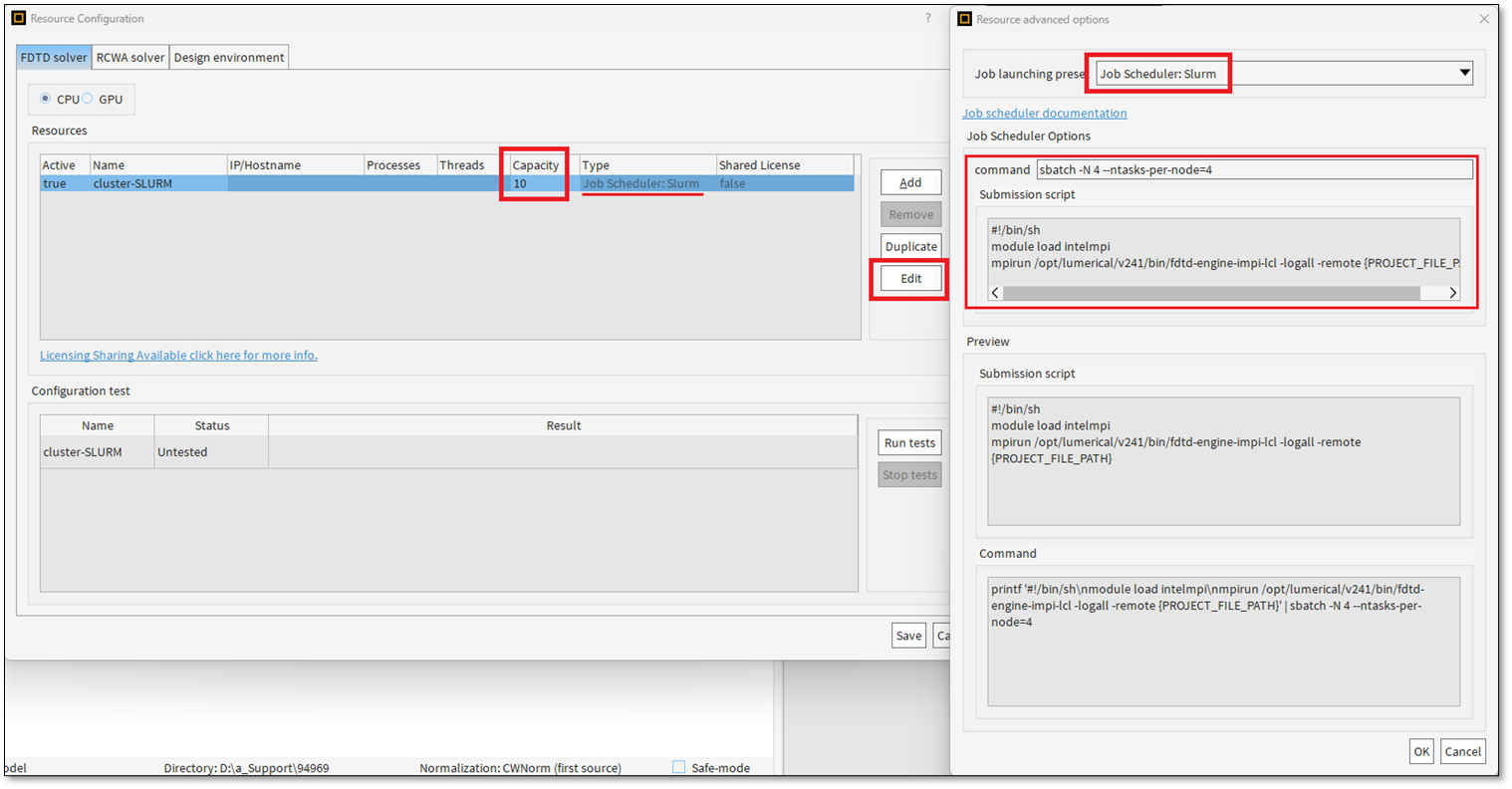
- 编辑高级资源设置 (advanced resource settings),从“作业启动预设” (Job Launching Presets) 中选择您的作业调度系统(例如 Slurm)。
注意事项:
- 预设会自动填充示例设置,可能不适用于您的特定集群。
- 请修改提交命令 (submission command) 以确保使用正确的节点数和每节点进程数,并更新提交脚本 (submission script) 以适应您集群和仿真需求的 Lumerical 计算环境。
- 使用 Slurm 提交作业时,请确保设置了请求计算集群资源的标志(例如 CPU、GPU 和内存),例如通过
--cpus-per-task、--gpus-per-node和--mem。 否则,仿真可能会失败或无法使用所有可用硬件。 有关请求资源的标志的更多信息,请参阅 Slurm 的sbatch文档。
从本地计算机向作业调度系统提交作业
如果您希望从本地计算机启动作业以获得更无缝的体验,可以按照与在集群上配置资源相同的步骤在本地计算机上配置 Lumerical,并通过设置 job_scheduler_input.json 文件来启用 SSH。
- 通过 JSON 文件进行配置的功能是在 Lumerical 2023 R2.2 版本中引入的。
- 对于之前的版本,您需要修改与您的作业调度系统相对应的
.py文件。 job_scheduler_input.json模板文件可以在 Lumerical 安装目录中找到:- Windows (默认安装路径):
C:\Program Files\Lumerical\v251\scripts\job_schedulers - Linux (默认安装路径):
/opt/lumerical/v251/scripts/job_schedulers
- Windows (默认安装路径):
job_scheduler_input.json 文件内容模板:
1
2
3
4
5
6
7
8
9
{
"user_name":"",
"use_ssh":0,
"use_scp":0,
"cluster_cwd":"",
"master_node_ip":" <master-node-ip> ",
"ssh_key":"~/.ssh/ <private-key> .pem",
"path_translation": ["",""]
}
重要步骤:
- 将
job_scheduler_input.json文件复制到您用户的 “home” 文件夹下对应的 Lumerical 配置路径:- Linux:
~/.config/Lumerical - Windows:
%APPDATA%\Lumerical
- Linux:
- 然后编辑该文件,填入您的作业调度系统设置。
job_scheduler_input.json 参数说明:
| 参数 | 描述 |
|---|---|
user_name |
您在主节点上的用户名。如果留空,将使用 import getpass; getpass.getuser() 动态分配用户名。 |
use_ssh |
如果设置为 1,则使用 ssh* 在主节点上运行提交命令。 |
use_scp |
如果设置为 1,仿真文件将使用 scp* 复制到主节点。 |
cluster_cwd |
当 use_scp=1 时,仿真文件将被复制到的共享文件夹路径,例如 """/cluster_path/of_simulationfile/"""。 |
master_node_ip |
用于远程连接和作业提交的主节点的 IP 地址或主机名。 |
ssh_key |
用于无密码连接的私钥文件的位置。 |
path_translation |
可用于在 Windows 共享文件系统与 Linux 集群之间转换路径。使用 Unix 风格的路径分隔符 /,例如 """path_translation"": [""local_path/of_simulationfile/"", ""/cluster_path/of_simulationfile/""]。 |
要从本地计算机向 Linux 集群提交作业,请将 use_ssh 和 use_scp 设置为 1,并将 master_node_ip 设置为节点的 IP 地址。 此方法将使用 scp* 将您的仿真文件复制到远程服务器,使用 ssh* 启动作业,并在结束时将所有生成的文件复制回您的本地计算机。
注意:在 Windows 上,您需要确保 SSH 和 SCP 已添加到系统的 PATH 环境变量中。 根据 Windows 的版本,您可以安装 Git Bash 或 OpenSSH for Windows。
结果
现在,您可以直接从 CAD 的作业管理器运行任何 Lumerical 仿真(单个、扫描、优化等)。
作业调度系统提交脚本 (SGE, Slurm, Torque, LSF)
作业调度系统脚本通常包含两个重要部分。 第一部分是设置作业运行的环境,第二部分是运行作业的命令。
以下示例利用了 IntelMPI 和 OpenMPI 提供的 mpirun 脚本。 由于我们在执行前设置了环境,因此无需提供 mpirun 的完整路径。 这些脚本会自动读取作业调度系统设置的环境变量并执行相应的 mpiexec 命令。
示例 1:AWS ParallelCluster 示例
1
2
3
#!/bin/sh
module load intelmpi
mpirun /opt/lumerical/v251/bin/fdtd-engine-impi-lcl -logall -fullinfo fdtd_100mb.fsp
示例 2:使用 MPI 环境脚本
许多 MPI 发行版中都可以找到 mpivars.sh 或类似的脚本。 此脚本会为其 MPI 发行版设置相应的 MPI 变量。
1
2
3
#!/bin/sh
source /opt/intel_2019/compilers_and_libraries_2019.3.199/linux/mpi/intel64/bin/mpivars.sh
mpirun /opt/lumerical/v251/bin/fdtd-engine-impi-lcl -logall -fullinfo fdtd_100mb.fsp
示例 3 (高级):使用 Modules 管理软件版本 您可以使用 Modules 来管理多个版本的 Lumerical 软件。 Modules 是集群管理中用于处理作业环境的常用工具。 您可以在这里找到有关如何创建 Modules 的更多信息:http://www.admin-magazine.com/HPC/Articles/Environment-Modules
1
2
3
4
#!/bin/sh
module load intel-mpi
module load lumerical-2019b
mpirun fdtd-engine-impi-lcl -logall -fullinfo fdtd_100mb.fsp
各调度系统运行命令
- Slurm:
1
sbatch -N {nodes} --ntasks-per-node={ppn} {submit.sh}
- Torque:
1
qsub -l nodes={n}:ppn={ppn} {submit.sh}
- SGE:
1
qsub -pe mpi {nodes*ppn} {submit.sh}
- IBM Platform/Spectrum LSF:
1
bsub -Ip -n {nodes*ppn} {submit.sh}
额外技巧:单命令提交作业 您也可以使用单个命令提交作业:
1
printf '#!/bin/sh\nmodule load intelmpi\nmpirun /opt/lumerical/v251/bin/fdtd-engine-impi-lcl -logall -fullinfo fdtd_1000000mb.fsp' | {job_scheduler_command}
