这是 DeepMind Scaling Book 系列的第 6 部分。
在 TPU 上训练 LLaMA 3 (Training LLaMA 3 on TPUs)
How To Scale Your Model Part 6 (Part 5: Training | Part 7: Inference)
让我们仔细看看如何利用我们在上一节中学到的知识,在 TPU v5p 上训练 LLaMA 3 模型。它们有多大?在不同配置下的训练有多昂贵?它们是如何分片的?让我们通过一些粗略的估算,看看前面的章节如何映射到真实模型上。
我们本节的目标是将上一节的结果应用于一个非常实际的问题:训练 LLaMA 3 系列 (herd) 模型。与前面的章节不同,我们希望你自己做很多工作。出于这个原因,我们隐藏了每个部分的答案,以便你可以先尝试回答。试着拿起笔,手工算一算!
LLaMA 3 长什么样? (What does LLaMA 3 look like?)
LLaMA-3 模型家族 [1] 包括 3 个主要模型:LLaMA 3 8B, 70B 和 405B。我们将主要关注 70B,把 8B 和 405B 留给你在最后的习题部分探索。这是 LLaMA 3-70B 的架构,取自 LLaMA HuggingFace 页面。
| hyperparam | value |
|---|---|
| \(n_\text{layers}\) (L) | 80 |
| \(d_\text{model}\) (D) | 8,192 |
| \(d_{ff}\) (F) | 28,672 |
| \(n_\text{heads}\) (N) | 64 |
| \(n_\text{kv_heads}\) (K) | 8 |
| \(d_\text{qkv}\) (H) | 128 |
| \(n_\text{embeddings}\) (V) | 128,256 |
为了突出这有多容易找到,这里是配置本身以及映射:
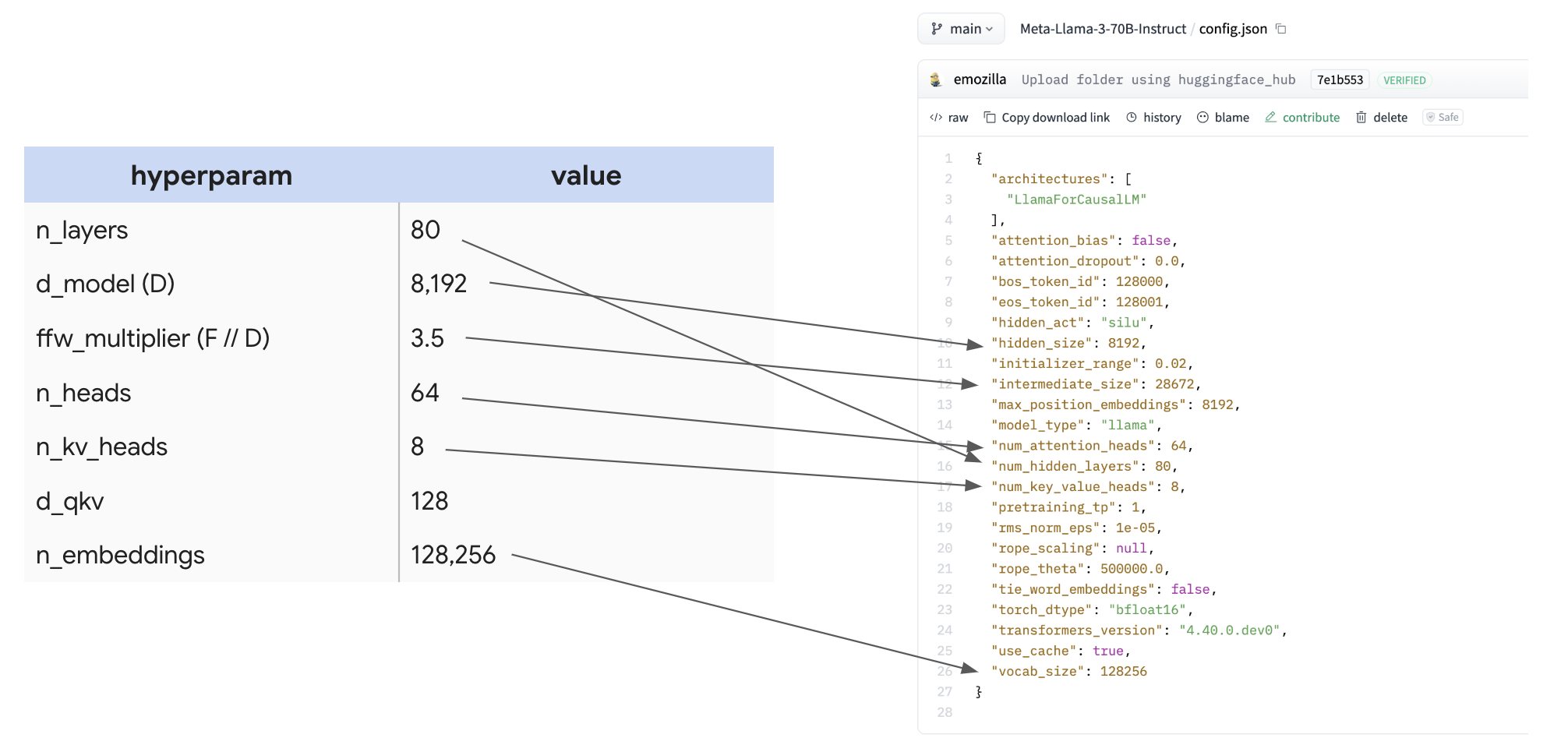
为许多不同的开源 LLM 制作一个包含这些数字的大表格是很有用的,这样你就可以快速比较它们所做的设计决策。
计算参数和 FLOPs (Counting parameters and FLOPs)
Question: 根据这个表格,我们可以计算 LLaMA 3-70B 的参数数量吗?🤫 让我们应用 第 4 节 的内容,看看我们是否能得到 70B!
| param | formula | count |
|---|---|---|
| FFW params | d_model * d_ff * 3 (for gelu + out-projection) * n_layers | 8,192 * 8,192 * 3.5 * 3 * 80 = 56.3e9 |
| Vocab params | 2 (input and output embeddings) * n_embeddings * d_model | 2 * 128,256 * 8,192 = 2.1e9 |
| Attention params | n_layers * [ 2 (for q embedding and concatenated output projection) * d_model * n_heads * d_qkv + 2 (for k and v) * d_model * n_kv_heads * d_qkv] | 80 * (2 * 8,192 * 64 * 128 + 2 * 8,192 * 8 * 128) = 12e9 |
| 56.3e9 + 2.1e9 + 12e9 = 70.4e9 |
太好了!我们得到了我们期望的数字。你会注意到,正如预期的那样,FFW 参数在总体参数计数中占绝对主导地位,尽管注意力也不是微不足道的。
Takeaway: MLP 块中的 3 个大权重矩阵比 Transformer 中的所有其他数组大得多,以至于我们在推理模型内存或 FLOPs 时通常几乎可以忽略所有其他参数。对于 LLaMA 3-70B,它们代表了 70B 参数中的 56B。
现在让我们看看 FLOPs!记住来自 第 4 节 的一般训练规则。
Question: LLaMA-3 每步训练每 token 执行多少 FLOPs?这有助于我们要确定整个训练过程有多昂贵。
点击这里查看答案,在你思考之后!
Answer: 如 第 4 节 所示,我们每 token 做大约 \(6 \cdot \text{param count}\) FLOPs,所以这里大约是 6 * 70e9 = 4.2e11 FLOPs / token。这大约是每步每 token 半个 TFLOP。假设我们是计算受限的,在单个 TPU v5p 芯片上,假设完美的 FLOPs 利用率,这大约需要 4.2e11 / 4.59E+14 = 1ms。
Question: LLaMA 3 训练了大约 15 万亿 (trillion) tokens。总共多少 FLOPs?
点击这里查看答案,在你思考之后!
Answer: 这很容易,就是 4.2e11 * 15e12 = 6.3e24 FLOPs 总共。6.3 yottaFLOPs。这很多!在单个 TPU 上,这将需要 6.3e24 / 4.59E+14 = 435 years。这也很多!
Question: 假设我们想在一个拥有 16x20x28 = 8960 个芯片的完整 TPU v5p pod 上进行训练。假设我们是计算受限的,在 bfloat16 中以 40% MFU 训练需要多长时间?
点击这里查看答案,在你思考之后!
Answer: 我们知道每个 TPU v5p 每秒可以执行 4.59e14 FLOPs。在 40% MFU 下,这将花费大约 T = 6.3e24 / (8960 * 4.59e14 * 0.4) = 3.8e6 seconds。这大约是 44 天! 考虑到我们可以实际达到 40% MFU,这相当合理。
Question: LLaMA 3-70B 是以大约 4M tokens 的 batch size 进行预训练的。我们需要多少 TPU 才能以此 batch size 进行训练?你可以假设 bfloat16 参数和 float32 优化器状态,并且你每层 checkpoint 梯度 4 次。
点击这里查看答案,在你思考之后!
Answer: 这个问题主要是在问内存使用情况,因为那是可用计算的唯一严格约束。在训练期间,我们有三个主要的 HBM 用途:模型参数、优化器状态和梯度检查点。如果我们假设 bfloat16 权重、float32 优化器状态和一个 非常 保守的梯度检查点方案(每层 4 次),我们有:
| Params | 2 * 70GB | ~140GB |
| Optimizer State | 8 * 70GB | ~560GB |
| Gradient Checkpoints | 2 * 8192 * 4e6 * 4 * 80 | ~20.9TB |
| Total | ~21.6TB |
总共大约是 21.6TB。你需要注意到,即使采用非常保守的检查点方案,梯度检查点也在内存图景中占据强烈主导地位。我们技术上可以每层做 1 个 checkpoint,或者做微批处理,但这不仅是合理的图景。有了这些假设,由于每个 TPU v5p 有 96GB HBM,我们需要 21.6e12 / 96e9 = 225 个 TPU。实际上并不多!
为什么我们不这样做? 嗯,因为它需要我们 44 days * 8960 / 225 = 1752 days 来训练。那几乎是四年。那是一大段时间。 不过,这清楚地表明我们使用这些大型集群不是因为我们受内存限制,而是因为我们需要额外的 FLOPs。
Question: 在与上述问题相同的假设下,如果我们使用 8960 个 TPU v5p 芯片,我们每芯片将使用多少内存?
点击这里查看答案,在你思考之后!
Answer: 我们的总内存仍然约为 21.6TB,所以每芯片我们将使用大约 2.4GB,这基本上什么都不是。如果我们做了更积极的检查点,例如每层 12 个 checkpoints,我们每芯片也只有 8GB。我们在这些规模的训练期间远未达到内存受限。
Takeaways: 在非常小的拓扑结构上训练甚至非常大的模型在技术上是可能的,但前提是它们可能需要很长时间。能够计算训练运行的总 FLOPs 允许我们通过假设适度的 MFU 和已知的拓扑结构来估算其训练时间。
如何为训练分片 LLaMA 3-70B (How to shard LLaMA 3-70B for training)
让我们坚持上面的设置,即我们想在 8960 个芯片的 TPU v5p pod 上以 4M token batch size(每 batch 1024 个长度为 4096 的序列)训练 LLaMA 3-70B。让我们讨论此模型的最佳分片策略是什么。
Question: 在上述假设下,我们可以单独使用 FSDP 训练我们的模型吗?首先,假设我们不能做任何序列/上下文并行。这应该是你的第一个想法,因为它很简单,如果可行,不会引入额外的通信。
点击这里查看答案,在你思考之后!
Answer: 这个答案有点学究气。如上所述,LLaMA 3-70B 最初是用 4K 长度的序列训练的,所以 4M tokens 的 batch size 给我们 1024 的 序列 batch size。这意味着我们实际上只能做纯数据并行/FSDP 直到 1024 个芯片,因为这就是我们要对其进行数据并行的序列数量。所以在简单的“没有额外通信的完全数据并行”意义上,答案是否定的。下一个问题将回答这个问题的稍微不那么学究的版本。
Question: 让我们放宽不做任何序列分片的要求。如果我们允许自己在 batch 和 序列轴上都做 FSDP,我们可以仅在 8960 个芯片上使用 FSDP 训练 LLaMA 3-70B 吗?
点击这里查看答案,在你思考之后!
Answer: 现在我们允许自己也做序列/上下文并行,我们可以扩展得更多。首先让我们计算我们的每设备 batch size。如果我们做 8960 路 FSDP,我们最终得到每 TPU batch size 为 4 * 1024 * 1024 / 8960 = 468 tokens。我们从上一节知道,当 \(\text{per device batch size} < 2550 / M_X\) 时,我们受 FSDP 的 ICI 限制。由于我们可以用完整的 3D pod 专用 3 个轴,这将给我们 850 的下限,我们远低于此。所以答案是否定的,即使有 3 个轴。我们将受到严重的通信限制。
Question: 现在让我们看看混合张量并行和 FSDP。是否存在某种组合让我们保持计算受限?如果是这样,我们应该做多少 FSDP 和张量并行?
点击这里查看答案,在你思考之后!
Answer: 首先让我们检查这是否甚至适合。我们知道如果我们的每芯片 batch size 小于 $2550^2 / 2F = 113$,我们将受通信限制。正如我们在上面看到的,我们略高于此。所以太好了!现在要选择最佳的 FSDP 数量,我们可以使用公式
\[X_{opt} = \sqrt{\frac{2BN}{F}} = \sqrt{\frac{2 \cdot 4.19e6 \cdot 8960}{28672}} = 1618\]四舍五入到合理的 2 的倍数,这给了我们大约 2048 路 FSDP 和 4 路张量并行。这应该很有效!
Takeaways: 我们可以在完整的 TPU v5p pod 上以 4M token batch size 训练 LLaMA-3,混合使用数据并行(1024 路)、序列并行(2 路)和张量并行(4 路),而不会受到通信限制。如果我们尝试做纯 FSDP 或 FSDP + 序列并行,我们将受通信限制。我们在上一节中炮制的方程非常实用。
练习题 (Worked Problems)
Question 1 [Scaling LLaMA 70B to more chips]: 假设我们想在具有相同 batch size 的 4 个 pod 上训练 LLaMA 3-70B。我们会使用什么并行方案?我们会是计算还是通信受限?训练大约需要多长时间?确使用正确的 roofline 界限。
Question 2 [LLaMA 405B]:
(a) 使用 LLaMA 3-405B config,如上编写一个包含所有关键超参数的表格。这个模型总共有多少参数?每训练步有多少 FLOPs?如果我们训练 15T tokens,我们执行多少 FLOPs?
(b) 假设我们想在 8 个 TPU v5p pod 上训练。我们会使用什么并行方案?训练需要多长时间?会是计算还是通信受限?
